react课程8-react基础知识
Last updated on October 1, 2024 am
本节课补充了一些关于React框架的基础知识。
一、DOM元素
文档对象模型(Document Object Model)元素是HTML或XML文档总的各个节点,这些节点代表文档的结构和内容。在浏览器中,DOM 提供了一种编程接口,使得开发者可以通过 JavaScript 动态地访问和操作页面内容。HTML 元素(如 <div>、<p>、<a> 等)在 DOM 中表示为元素节点。
通过 JavaScript,开发者可以使用各种方法和属性来操作 DOM 元素,以动态修改页面内容和结构。例如:
- 选择 DOM 元素:可以使用
document.getElementById()、document.querySelector()等方法选择特定的 DOM 元素。 - 修改内容或样式:可以通过修改
innerHTML、textContent或style属性来更改元素的内容或样式。 - 添加或移除元素:可以使用
appendChild()、removeChild()等方法向 DOM 中添加或移除元素。 - 事件处理:可以为 DOM 元素添加事件监听器来处理用户交互事件(如点击、输入等)。
二、Hook
React 中的 Hook 是一组特殊的函数,它们允许你在函数组件中使用 React 的状态和其他特性,而无需编写类组件。Hooks 是 React 16.8 版本引入的,目的是简化代码并使组件更容易理解和复用。
1、为什么使用 Hooks?
- 函数组件的局限性:在 Hooks 引入之前,只有类组件可以使用状态和生命周期方法。而函数组件则只能处理简单的、无状态的逻辑。
- Hooks 的优势:通过 Hooks,你可以在函数组件中使用状态、管理副作用、以及访问组件生命周期等功能。这使得函数组件可以替代类组件,并且更易于编写、复用和测试。
2、常见的 Hooks
**
useState**:用于在函数组件中添加状态。**
useEffect**:用于在函数组件中处理副作用,比如数据获取、订阅或手动修改 DOM。它相当于类组件中的componentDidMount、componentDidUpdate和componentWillUnmount。**
useContext**:允许你在函数组件中使用 React 的上下文(Context),从而避免通过组件树逐层传递数据。**
useReducer**:用于在函数组件中管理更复杂的状态逻辑,是useState的替代方案。它类似于 Redux 的 reducer 概念。
3、Hooks 的规则
- 只能在函数组件或自定义 Hook 中调用:不能在普通的 JavaScript 函数、类组件或循环、条件语句中调用 Hook。
- 必须在顶层调用:不能在嵌套的函数或代码块中调用 Hook。这是为了保证每次渲染时 Hook 的调用顺序一致,从而确保状态和副作用的正确性。
三、Reconciler
在 React 中,reconciler 是一个内部机制,负责比较和协调(reconcile)组件状态变化时的 UI 更新过程。它是 React 核心部分之一,帮助确定在每次渲染时需要更新哪些部分的 UI,以及如何最有效地进行这些更新。
1、Reconciler 的主要作用
- 差异计算(Diffing):当 React 组件的状态或属性发生变化时,Reconciler 负责比较新旧虚拟 DOM 树,找出两者之间的差异。这一过程称为“diffing”。
- 最小化更新:通过 diffing 计算,Reconciler 可以确定最小化的更新集,即需要修改的节点,而不是重新渲染整个 UI。这提升了性能,尤其是在大型复杂应用中。
- 触发渲染更新:根据 diffing 的结果,Reconciler 会告诉渲染器(renderer)哪些 DOM 操作需要执行,从而更新页面的 UI。对于 web 应用,渲染器通常是 React DOM。
2、工作原理
Reconciler 的核心在于如何有效地计算出旧的虚拟 DOM(virtual DOM)树与新的虚拟 DOM 树之间的差异,并生成需要对实际 DOM 进行的更新操作。主要包括以下几个步骤:
- 虚拟 DOM:React 使用虚拟 DOM 来表示用户界面的结构。虚拟 DOM 是一个轻量级的 JavaScript 对象树,描述了 UI 的当前状态。
- 比较(Comparing):当组件状态或属性更新时,React 会创建一棵新的虚拟 DOM 树。Reconciler 然后会比较新旧两棵树,找出它们之间的差异。
- 差异计算(Diffing):Reconciler 使用了一种高效的算法,称为“diffing”,来找出哪些节点改变了。这包括节点的增删改、属性变化等。
- 更新(Updating):根据 diffing 的结果,Reconciler 会生成一系列操作指令(例如插入节点、删除节点、更新属性等),这些指令将被传递给渲染器,渲染器最终会将这些变化应用到实际的 DOM 中。
3、协调过程
Reconciler 主要负责协调虚拟 DOM 树的更新过程,确保 UI 的更新是高效且一致的。协调过程包括以下内容:
- 树比较:Reconciler 会递归地比较新旧虚拟 DOM 树,找出需要更新的部分。对于每一个不同的部分,它会生成一个更新指令。
- 键值(Key)优化:当渲染列表时(例如使用
map()渲染多个元素),Reconciler 使用key属性来跟踪每个元素,从而更高效地更新列表项。这避免了不必要的节点重排和重渲染。 - 递归更新:Reconciler 递归地更新所有子节点,确保整个组件树都得到适当的更新。
4、Fiber 架构
React 16 版本引入了新的 Fiber 架构,增强了 Reconciler 的功能,使其能够更好地处理大型更新任务,并支持中断任务、优先级处理等高级特性。Fiber Reconciler 的主要改进包括:
- 可中断渲染:Fiber 架构允许 React 将长时间运行的渲染任务分成多个小任务,从而在渲染过程中可以响应用户的交互。
- 任务优先级:Fiber 允许为不同的更新任务设置优先级,使得更重要的任务可以被优先处理。
总结
在 React 中,Reconciler 是一个关键的内部机制,负责管理和优化组件更新的整个过程。它通过高效的 diffing 算法最小化 DOM 操作,确保页面更新既快速又高效。React 的 Fiber 架构进一步提升了 Reconciler 的性能和灵活性,使得 React 能够更好地处理复杂的应用场景。


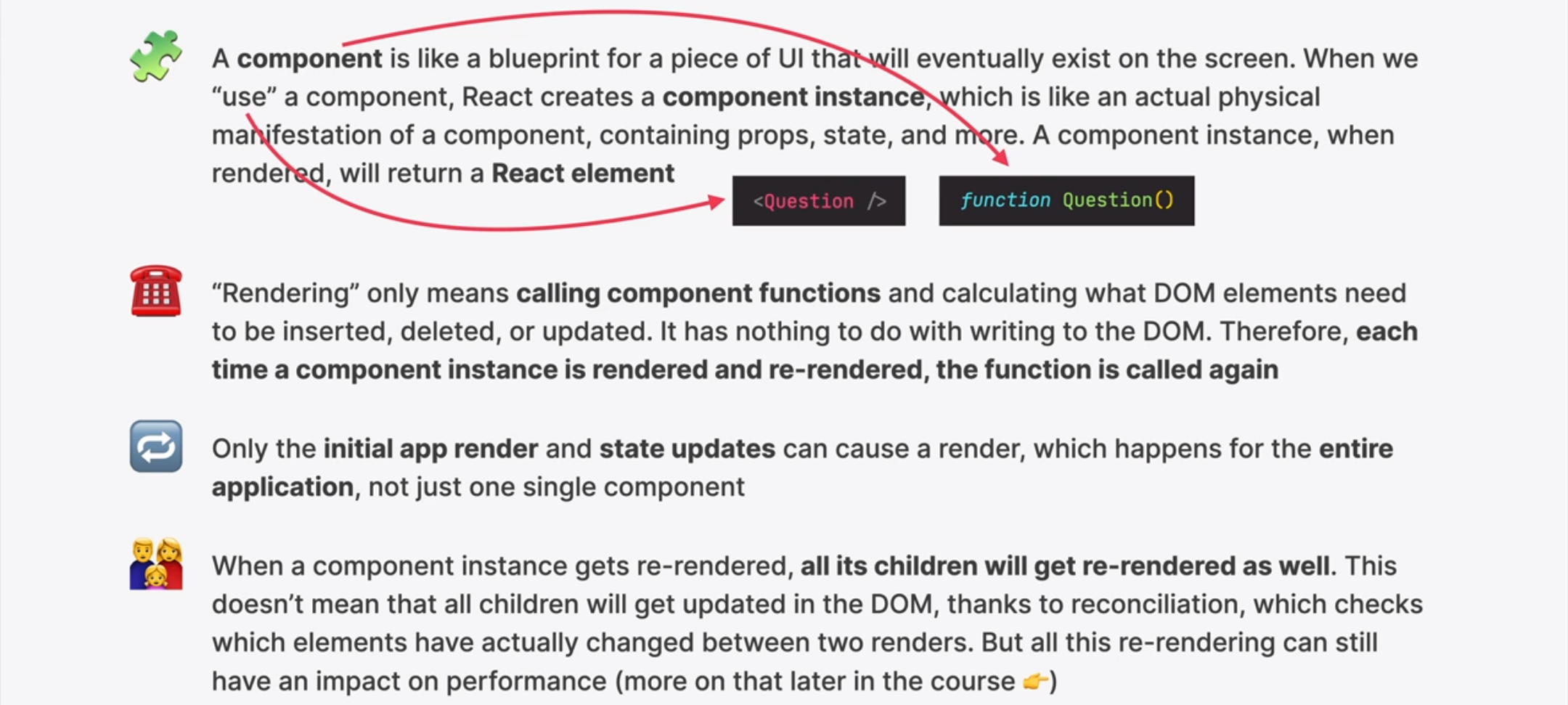


四、side effect
在 React 中,“side effect”(副作用)通常指的是组件在渲染过程中执行的那些与渲染无关的操作。副作用包括但不限于以下情况:
- 数据获取(Data Fetching): 例如,你在组件渲染后从 API 获取数据。
- 订阅(Subscriptions): 例如,订阅某个事件或数据源,在组件卸载时取消订阅。
- 手动更改 DOM: 虽然 React 通常会管理 DOM 操作,但有时你可能需要手动更改 DOM,如操作第三方库或者直接使用
document对象。 - 定时器(Timers): 使用
setTimeout或setInterval设置定时器。
在 React 中,处理副作用最常用的方式是使用 useEffect 钩子。useEffect 钩子允许你在函数组件中执行副作用,并在必要时清除这些副作用。
五、依赖数组
useEffect 是 React 中用于处理副作用的钩子,比如数据获取、订阅、手动更改 DOM 等。依赖项数组决定了 useEffect 中的回调函数何时执行。
空数组 []:
- 如果依赖项数组为空,
useEffect中的回调函数只会在组件首次渲染后执行一次。 - 相当于组件的
componentDidMount生命周期钩子。
没有依赖项数组:
- 如果不提供依赖项数组,
useEffect中的回调函数将在每次组件渲染后执行。 - 相当于每次组件更新后的
componentDidUpdate。
带有依赖项的数组 [dep1, dep2, ...]:
- 如果依赖项数组中包含特定的变量,
useEffect中的回调函数只有在这些变量发生变化时才会执行。 - 这可以优化性能,避免不必要的副作用执行。
六、stale closure
“Stale closure” 是 React 开发中一个常见的术语,指的是在使用 React hooks(尤其是 useEffect、useCallback、useMemo 等)时,闭包(closure)中引用了过时的变量或状态值,导致逻辑错误。
闭包是 JavaScript 中一个函数可以记住其创建时的上下文的特性。闭包使得内部函数可以访问外部函数的变量,即使外部函数已经执行完毕。这种特性在 React hooks 中可能会导致问题,尤其是在依赖项数组没有正确设置时。
在 React 中,组件的每次渲染都会生成新的函数和新的闭包。闭包中捕获的变量值是函数创建时的那一刻的值,而不是当前渲染的最新值。如果你的组件多次渲染,而某个钩子函数内部的闭包引用了旧的变量或状态值,那么这个闭包就被称为“stale closure”(陈旧的闭包)。
解决方法:
函数式更新: 当使用 setState 时,使用函数式更新(即传递一个函数而不是直接传递新值)。这可以确保你总是基于最新的状态更新。
正确设置依赖项数组: 在 useEffect、useCallback 和 useMemo 等 hooks 中,确保依赖项数组包含所有在闭包中引用的状态或 props。这样 React 就会在依赖项变化时重新执行函数,避免使用陈旧的闭包。
使用 refs: 在一些场景下,你可以使用 useRef 来存储值,因为 useRef 中的值在渲染之间是持久的,并且更新时不会触发组件的重新渲染。
七、派生态
在React中,**”derived state”(派生状态)**通常是指通过计算或处理组件的已有状态或props得出的新数据,而不是直接存储在组件的state中的数据。派生状态不应该存储在state中,因为它可以在渲染时通过计算得出,从而避免冗余和潜在的数据不一致性。
八、useState初始化状态
方法一:使用函数初始化
1 | |
方法二:直接初始化
1 | |
惰性初始化(Lazy Initialization):
- 方法一使用的是惰性初始化。
useState接受一个函数作为参数时,React会在组件初次渲染时调用该函数,并将其返回值作为初始状态。这意味着函数只会在组件首次渲染时执行一次。 - 方法二中的
localStorage.getItem和JSON.parse在组件每次渲染时都会执行,即使状态已经初始化,这在某些情况下可能会导致不必要的计算开销。
性能考虑:
- 方法一更适合在初始化过程中存在昂贵操作(例如复杂的计算或数据提取)时使用,因为这些操作只会在组件首次渲染时执行一次。
- 方法二的性能可能稍微差一些,尤其是在有复杂操作时,因为每次渲染组件都会执行状态初始化的表达式。
代码的可读性:
- 方法一可能更具可读性,特别是当初始化逻辑比较复杂时,使用函数形式可以让代码更清晰,容易理解逻辑分步处理的过程。
- 方法二在简单的初始化场景下代码更简洁。
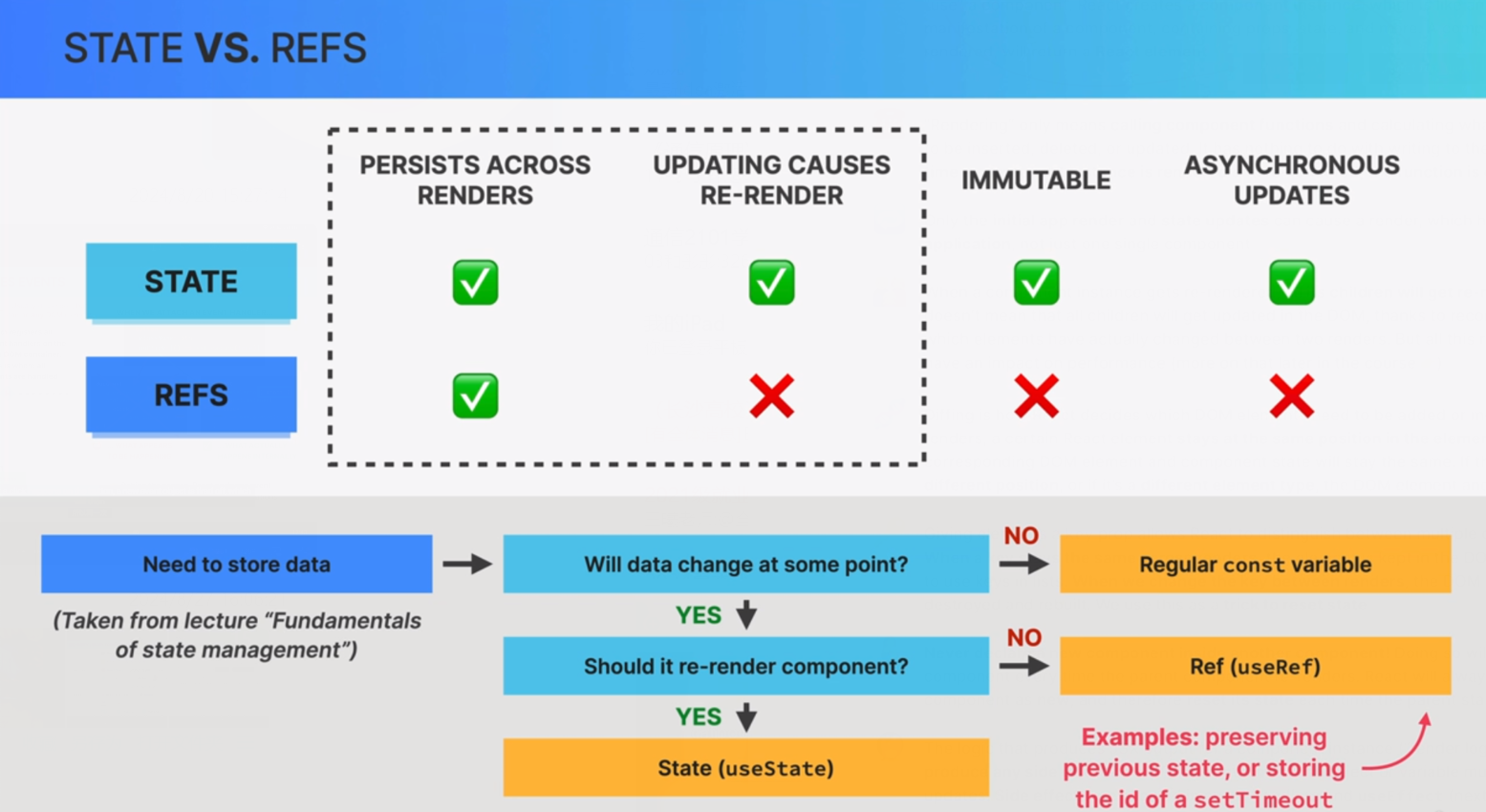
九、useRef
特点:
保持跨渲染的可变值:
useRef返回的对象是{ current: value }。这个对象在组件的整个生命周期内是持久的,更新current属性不会触发重新渲染。这使得useRef非常适合存储跨渲染周期的数据,比如计时器ID、上一次的状态值或某个DOM节点的引用。
访问DOM元素:
useRef常用来直接访问DOM元素。在上面的例子中,我们使用ref属性将myRef对象赋给了一个输入框。myRef.current指向该DOM元素,可以在按钮点击时调用focus()方法来聚焦输入框。
保存组件间不变的数据:
useRef可以用来保存不需要触发重新渲染的变量。例如,你可以使用useRef保存计数器值或状态变量的前一个值,而无需通过useState来管理它们。
十、Custom Hooks(自定义钩子)
当多个组件需要共享相似的逻辑时,可以将这些逻辑提取到一个自定义Hook中,以避免重复代码。例如,处理表单输入的状态、处理数据获取(如API请求)的逻辑等。
十一、Fiber
React 的 Fiber 是 React 16 及其后续版本中的一种新架构,用于提升 UI 渲染的性能和灵活性。它重新设计了 React 的协调(reconciliation)算法,使得 React 能够更好地处理复杂的应用场景,尤其是在响应用户交互和更新大型组件树时。Fiber 是一种数据结构和执行机制,它使得 React 可以更细粒度地管理和调度组件的更新任务。与传统的同步渲染不同,Fiber 允许将更新任务拆分成多个小任务,并根据优先级有选择地执行,从而提高了应用的响应性。
(1) Fiber 的设计目标
Fiber 架构的设计目标主要包括以下几个方面:
- 可中断渲染:传统的 React 采用的是同步递归算法,这意味着一旦开始渲染,就会阻塞主线程,直到整个渲染过程完成。Fiber 通过将渲染任务切割成多个小片段,使得渲染过程可以被中断,从而在必要时让出时间给其他更高优先级的任务。
- 任务优先级:Fiber 允许为不同的更新任务设置优先级。优先级较高的任务(例如用户交互)可以在低优先级任务(例如后台数据同步)之前执行,从而提升用户体验。
- 并发模式:Fiber 为 React 引入了并发模式,使得 React 能够在后台渲染任务时处理用户输入或其他高优先级任务,从而减少页面卡顿现象。
(2) Fiber 的工作原理
Fiber 将组件更新的工作分成两个主要阶段:渲染阶段(Render Phase) 和 提交阶段(Commit Phase)。
- 渲染阶段:
- 在这个阶段,React 会通过协调器(Reconciler)进行组件树的 diffing(比较),决定哪些部分需要更新。
- 这个过程是“可中断的”,即 React 可以暂停渲染,以便处理其他更紧急的任务,然后再继续渲染未完成的部分。
- 提交阶段:
- 一旦渲染阶段完成,React 会进入提交阶段,在这个阶段,所有的更改都会被应用到实际的 DOM 中。
- 这个阶段是同步的,并且不可中断,因为它直接影响到用户界面的显示。
(3)Fiber 数据结构
Fiber 是一种链表结构,每个组件实例对应一个 Fiber 节点。Fiber 节点包含了关于该组件的各种信息,例如:
- 类型(Type):组件的类型,例如函数组件、类组件或原生 DOM 节点。
- 状态(State):组件的本地状态和挂载点。
- 子节点、兄弟节点和父节点的引用:用来构建 Fiber 树。
- 更新队列(Update Queue):保存该 Fiber 节点上的所有状态更新。
(4)优先级调度
Fiber 通过一个叫做 scheduler 的机制来管理不同更新任务的优先级。Scheduler 会根据任务的重要性为其分配优先级,并确保高优先级任务优先执行。
- 高优先级任务:例如用户的输入和动画,这些任务需要快速响应,因而具有较高优先级。
- 低优先级任务:例如网络请求或不紧急的状态更新,这些任务可以在空闲时间执行。
(5)可中断渲染和恢复
Fiber 的核心优势在于其可中断性。当 React 在渲染某个组件时,如果遇到一个更高优先级的任务,它可以暂停当前任务,将控制权交给高优先级任务。在高优先级任务完成后,React 可以恢复之前的渲染,继续未完成的工作。
(6)Concurrent Mode(并发模式)
Fiber 还为 React 引入了并发模式(Concurrent Mode)。并发模式下,React 可以在后台并发地处理多个渲染任务,并在处理任务的同时继续响应用户输入。这样可以显著提升应用的流畅性和响应速度。
(7)Fiber 的优缺点
优点:
- 提高了渲染的灵活性:通过可中断和恢复渲染,React 可以更好地管理大型更新任务。
- 减少卡顿:通过任务优先级调度和并发模式,Fiber 减少了 UI 更新时的卡顿现象。
- 增强用户体验:Fiber 提供了更高效的用户界面更新机制,尤其是在处理大量状态变化时。
缺点:
- 复杂性增加:Fiber 引入了更多的内部机制,增加了 React 内部的复杂性。
- 需要适应新模式:开发者需要理解 Fiber 的工作原理,以便在复杂应用中更好地使用 React。
十二、Fiber Tree
Fiber Tree 是由多个 Fiber 节点相互连接而形成的树形数据结构。与传统的 Virtual DOM 树不同,Fiber Tree 允许对渲染工作进行分片处理,支持中断、恢复、以及优先级调度等操作。这使得 React 能够更有效地处理复杂的 UI 更新场景。
每个 Fiber 节点包含了一些描述组件的信息和状态,它们主要包括以下几个部分:
- Type:
- 表示组件的类型,如函数组件、类组件或原生 DOM 元素。
- Key:
- 用于在同级组件中标识节点,以便在更新时可以高效地进行 diff 运算。
- StateNode:
- 指向与当前 Fiber 节点对应的组件实例或 DOM 元素。
- Return:
- 指向当前 Fiber 节点的父节点。
- Child:
- 指向当前 Fiber 节点的第一个子节点。
- Sibling:
- 指向当前 Fiber 节点的下一个兄弟节点。
- PendingProps 和 MemoizedProps:
- 分别表示当前更新的 props 和上一次渲染时的 props。
- UpdateQueue:
- 存储需要在当前节点上处理的状态更新或副作用。
- Alternate:
- 指向 Fiber 树中的另一个对应节点,这在双缓冲技术(double buffering)中用于管理更新时的 Fiber。
Fiber Tree 的工作原理
在 React 中,Fiber Tree 主要用于以下几种场景:
- 协调过程(Reconciliation):
- 当组件状态或 props 发生变化时,React 会通过 Fiber Tree 来进行 diff 运算,以确定哪些部分需要更新。这个过程是可中断的,因此 React 可以优先处理高优先级任务。
- 任务调度:
- Fiber Tree 通过
scheduler管理不同任务的优先级,并决定哪些任务应该首先执行。
- Fiber Tree 通过
- 双缓冲技术:
- Fiber Tree 通过
current和workInProgress两棵树进行双缓冲。current是当前屏幕上显示的 Fiber 树,而workInProgress则是正在构建的 Fiber 树。当新的更新完成时,React 会交换这两棵树。
- Fiber Tree 通过
构建和更新 Fiber Tree 的过程
- 初次渲染:
- React 会创建整个 Fiber Tree,并构建组件的实例以及它们对应的 DOM 元素。
- 更新过程:
- 当组件状态或 props 改变时,React 会创建一棵新的 Fiber Tree,并与旧的 Fiber Tree 进行对比。这种对比可以高效地找出需要更新的部分。
- 提交阶段:
- 在更新 Fiber Tree 后,React 会将变化应用到真实的 DOM 上。这是不可中断的阶段,确保用户界面与最新状态同步。
Fiber Tree 的优势
- 性能优化:
- Fiber Tree 允许对 UI 更新进行分片处理,避免了长时间的主线程阻塞,提升了页面的响应性。
- 优先级调度:
- React 可以根据任务的优先级来决定执行顺序,从而确保用户的交互优先得到响应。
- 渐进渲染:
- Fiber Tree 支持并发模式,使得 React 可以渐进式地渲染大型组件树。
十三、Key的重要性
在 React 中,key 是一个特殊的属性,用于帮助 React 高效地更新和渲染列表中的元素。它在列表渲染和组件的重新排序中发挥了重要作用。以下是 key 的几个重要作用:
- 帮助 React 识别元素
key 属性帮助 React 唯一标识列表中的每个元素。它用于区分每个元素,从而帮助 React 确定哪些元素已经改变、添加或删除。这使得 React 在更新界面时能够更高效地进行操作。
- 提高渲染效率
当列表的内容发生变化时(如增加、删除或重新排序),React 依赖 key 来确定哪些元素需要重新渲染。如果没有 key,React 会重新渲染整个列表,这样会降低性能。使用 key,React 能够最小化 DOM 操作,仅更新实际变化的部分。
- 稳定组件状态
key 有助于确保组件的状态在渲染过程中保持稳定。例如,如果一个列表中的元素被重新排序,但它们的 key 不变,React 会保持这些元素的状态,而不是重新创建它们。这样可以避免组件状态的丢失或重置。
- 唯一性要求
key 属性的值必须在列表中唯一,但不必在整个应用中唯一。通常,key 是元素的唯一标识符(如 ID),或者基于元素内容生成的唯一值。使用不唯一的 key 会导致 React 无法正确识别和管理元素,从而可能导致性能问题或不一致的 UI。